
When we interact with AI models like ChatGPT, it feels like we’re exchanging sentences in natural language — English, Hindi, or any other tongue.
But actually, these models don’t understand words the way we do. They see the world through something far more granular: tokens.
Understanding this difference — between “a word” and “a token” — can help you write better prompts, optimize your AI costs, and interpret model behavior more effectively.
What’s a Word?
A word is how humans think of language.
It’s a complete linguistic unit with meaning, structure, and context.
Examples:
- cat
- running
- unbelievable
Each is a single word in human language — but for an AI, things aren’t so simple.
What’s a Token?
A token is a chunk of text that an AI model processes — a unit that could represent:
- a full word (e.g.
cat), - a part of a word (e.g.
un,believ,able), or - even punctuation or whitespace (e.g.
.or" ").
Tokens are what get converted into numbers before feeding them into the model.
This process — called tokenization — allows the model to operate on text mathematically.
Example:
Let’s take a short sentence:
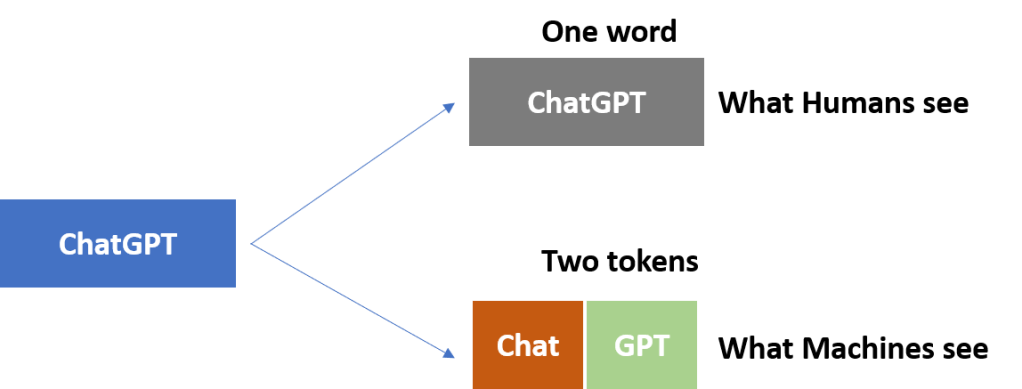
“ChatGPT is amazing”
For you and me, that’s three words.
“ChatGPT is amazing” -> [“ChatGPT”, “is”, “amazing”]
But for a model, depending on the tokenizer, it might become something like:
“ChatGPT is amazing” -> [“Chat”, “GPT”, ” is”, ” amazing”]
So, while we see 3 words, the model sees 4 tokens.
This subtle difference is crucial — every token counts towards your input/output budget in models like GPT-4 or Claude.
Why Does It Matter?
Here’s why understanding tokens helps both technically and practically:
- Prompt Length & Cost
Pricing in most AI models (like OpenAI, Anthropic) is token-based, not word-based.
Fewer tokens → lower cost and faster responses. - Performance Optimization
Efficient token use can reduce context overflow and improve prompt clarity. - Better Prompt Writing
Knowing how tokenizers split text helps you write prompts that stay within limits — especially in long instructions or large datasets. - Debugging Model Behavior
Sometimes weird outputs arise because your prompt got tokenized differently than expected.
How Tokenization Works
Tokenization algorithms, like Byte Pair Encoding (BPE) or WordPiece, break text into frequently occurring subword units.
They help handle rare words, misspellings, or variations efficiently.
For example:
“Unbelievable” →
["un", "believ", "able"]
This makes it easier for models to generalize meanings across related words like believe, believable, or unbelievably.
A Handy Rule of Thumb
Roughly speaking:
1 token ≈ 4 characters in English, or ≈ ¾ of a word.
So, a 1000-word article might contain about 1300–1500 tokens — depending on spacing, punctuation, and language.
Key Takeaway
Think of words as what humans use, and tokens as what machines understand.
Word → Meaning for humans
Token → Math for machines
When you prompt an AI, it’s reading tokens — not words — and every token shapes how it understands your request.


Leave a comment